Open EDR Components
This post describes the architecture of Open EDR components. The documentation for a component usually includes an information which is enough for understanding how it works and for developing it. However, these documents don’t include the precise API of particular component or details of implementation if it is not necessary for understanding the generic working scenario of it. The API is provided by the autogenerated documentation.
The API of components and implementation details (including code samples) are described in the source code (as comments). The automatic documentation generator uses these sources for generation documents. These documents can be found in appropriate API documents.
Components
The Open EDR consists of the following components:
- Runtime components
- Core Library – the basic framework;
- Service – service application;
- Process Monitor – components for per-process monitoring;
- Injected DLL – the library which is injected into different processes and hooks API calls;
- Loader for Injected DLL – the driver component which loads injected DLL into each new process
- Controller for Injected DLL – service component for interaction with Injected DLL;
- System Monitor – the genetic container for different kernel-mode components;
- File-system mini-filter – the kernel component that hooks I/O requests file system;
- Low-level process monitoring component – monitors processes creation/deletion using system callbacks
- Low-level registry monitoring component – monitors registry access using system callbacks
- Self-protection provider – prevents EDR components and configuration from unauthorized changes
- Network monitor – network filter for monitoring the network activity;
- Installer
Generic high-level interaction diagram for runtime components
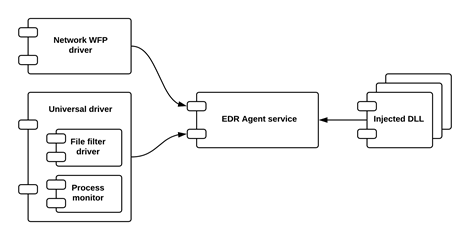
* The service initializes and uses other components for collecting data, providing the response and for other functions.
Core Library Architecture
Core library contains the basic framework functionality. Agent application uses the library libcore as a base. This library provides OS-abstraction layer for the application’s code. All provided functions are OS-independent. The most of OS-specific interactions are hidden on the libcore level.
Basic data objects
The basic data objects are the elements for building the abstract data container – Data Packet. It is used for exchanging information between c++ objects/components (for example, for storing/accessing configuration data, C++ representation of data which is received from (sent to) service components). The data packet is an hierarchical storage for the following objects:
- Scalars:
- Signed integer (64-bit)
- Unsigned integer (64-bit)
- Boolean
- Empty value
- Pointer to object – is a smart shared pointer to the any external object from common objects’ hierarchy (IObject).
- Containers
- Dictionary – is an container of elements which provides an unordered access to its elements by a string key. It’s like a std map container.
- Sequence – is an container of elements which provides an ordered access to its elements by an index. It’s like a std vector container.
In general, Data Packet is like fast JSON object which also can contain pointers to object and provides additional features (thread-safe, fast string access, different string encoding support, the special object interface support, etc.).
All these types are wrapped by a single object – Variant. The Variant is a universal lightweight type which implements reference semantic for storing and accessing these elementary objects. Dictionary and Sequence types are just wrappers for the Variant. Under the hood, the Variant uses internal BasicDictionary and BasicSequence objects which in turn use standard C++ containers for storing the data.
Example of objects hierarchy
Dictionary,
Scalar,
Scalar,
Pointer,
Sequence,
Dictionary,
Scalar,
Sequence,
Scalar,
Scalar,
Scalar,
Dictionary,
Dictionary,
Scalar,
Dictionary,
Scalar,
ScalarReference semantic
The Variant uses the reference semantics. For all types excepting some scalar ones (integers, booleans), the variant stores the smart pointer to the underlying data object. In the case of copy/assign operations, the shallow copy of the object is created. So the Variant class has a minimal performance impact during copy/move operations and we can use passing the Variant parameters by value. For some scalar types (integers, booleans) the Variant performs the full copy of the internal value.
Important to know that the Variant by itself isn’t thread-safe. All operations with a Variant variable should be synchronized. However, the copy of the same Variant object can be used safely alongside the original object. This is reached by using the approach “copy-on-write” for scalar types and internal synchronization mechanisms for basic containers.
As said above, the Variant creates shallow copy during copying/assignment operations. However, it also has functional of deep copying – object cloning. In this case, the full copy of all hierarchy of the Variant object is created.
Basic objects creation and conversion
Due to its nature, the basic containers aren’t included in the common objects hierarchy and don’t provide abstract interfaces. These objects are created by their standard constructors. The constructors support the std::initialization_list notation.
The basic objects support conversion between each other with some limits:
- Scalar → Sequence (with this one source scalar inside);
- Dictionary → Sequence (with the values of the source Dictionary);
- Signed integer ↔ Unsigned integer
Access to containers’ data
For easy and convenient access to data in containers, the Variant supports accessing to data using operator [] (the analog of get(index) function). For the Sequence, the index is an integer and for the Dictionary is a string. If the element with a specified index is not found the exception is thrown. However, the Variant has an overloaded version of get() function with the second parameter. This function doesn’t throw an exception. This second parameter is a default value for the requested parameter and is used as a return value if the specified key is not found.
auto nSize = queue["size"]; // throws exception if queue doesn't have a field 'size'
auto nSize = queue.get("size", 0); // returns 0 if queue doesn't have a field 'size' All basic objects can include each other (excluding scalar primitives) creating the data hierarchy. The operator [] can be used for accessing data inside hierarchy:
auto nSize = config["services"]["queueManager"]["queues"][2]["size"];Iterators
The Variant provides the iterators for internal containers. The standard begin()/end() semantic is used. There are two types iterators of supported: thread-safe iterator and thread-unsafe iterator. The safe iterator unlike the unsafe one, provides synchronization during the iteration process. It means that the iterable sequence of elements remains constant. For doing that the safe iterator creates the shallow copy of the iterable container. Important to know, that iterators provide read-only access to container items.
Strings encoding
The basic data objects use UTF-8 encoding for representing string data. UTF-8 encoding is used as the most universal and cross-platform method of storing strings. However, the Windows OS uses the UTF-16 encoding as a base. The conversion between UTF-8 ↔ UTF-16 can be resource-intensive if it performs each time then we access the data. So for optimization conversion operations, the basic objects shall store both types of strings as values. Initially, the string saved to the basic object using the original encoding. However, when the string is requested using another type than its native encoding, the basic data object converts it to the requested encoding and also saves the result into the cache. This cache will be used for processing further requests. If the string changes, the cache is invalidated.
Important to know that all keys in Dictionary objects can have only 1-byte ANSI encoding (which a subset of UTF-8).
Proxy interfaces for data access
Some objects from the common objects hierarchy can provide the Dictionary-like and Collection-like access to their data. The Variant supports a transparent access that objects using special proxy interfaces. If the Variant stores the pointer to an object and this object provides one of the proxy interfaces, the Variant redirects all data requests to this object using this proxy interface. This ability allows to represent external data sources as data packets and provide the common single way of access to data.
- IDictionaryProxy interface provides access to a data set using string keys. It allows to get/put/iterate data, get a size of the container and so on (see API section);
- ISequenceProxy interface provides access to a data set using integer indexes; It allows at least the same operations as IDictionaryProxy;
- IDataProxy interface provides the read-only access to one data field. This data is provided by an external object and can be dynamic. This technique can be used, for example, for dynamically calculated data fields.
Proxy objects
Proxy objects can be used for monitoring and controlling the access to the data in the data packets. There are several obvious examples of usage such as:
- Creating read-only data objects (entire object or selected data fields);
- Monitoring and hooking read/write access to data and changing parameters and results on-the-fly;
All proxy objects are based on using proxy interfaces described above.
Dictionary proxy object
Dictionary proxy object can wrap any Dictionary object or object based on IDictionaryProxy. It allows to set the following functions-handlers:
- data preModify(sKeyName, data) – calls when the sKeyName field tries to be written into the base dictionary object. The handler can throw an exception (if the write operation is not allowed);
- void postModify(sKeyName, data) – calls when the sKeyName field was written from the base dictionary object. The handler can’t change the result of operation but can register the fact of data changes.
- void preClear() – calls when the clear() function is called and before clearing of the base dictionary. The handler can throw an exception (if the clearing is not allowed);
- void postClear() – calls when the clear() function is called and after clearing of the base dictionary. The handler can’t change the result of operation but can register the fact of data changes;
- void createDictionaryProxy(data) – calls when an inner dictionary value is requested from the base dictionary If the handler is omitted no proxy will be created for any of inner dictionary values.
- void createSequenceProxy(data) – calls when an inner sequence value is requested from the base dictionary. If the handler is omitted no proxy will be created for any of inner sequence values.
For each returned Dictionary-like and Sequence-like object the proxy object creates a new wrapper (using new proxy object with the same settings as an original one) and returns it. It allows to control access to data for all descendant fields of complex data object.
Sequence proxy object
Sequence proxy object can wrap any Sequence object or object based on ISequenceProxy. It allows to set the following functions-handlers:
- data preModify(nIndex, data) – calls when the nIndex item tries to be written into the base sequence object. If the item is being deleted, then the data is null. The handler can throw an exception (if the write operation is not allowed);
- void postModify(nIndex, data) – calls when the nIndex item was written from the base sequence object. If the item is being deleted, then the data is null. The handler can’t change the result of operation but can register the fact of data changes.
- int preResize(nSize) – calls when the setSize() function is called and before resizing of the base sequence. If the size is 0 then the handler may be called for handling clear() call. The handler can throw an exception (if the size changing is not allowed) or return a new size;
- void postResize(nSize) – calls when the setSize() function is called and after resizing of the base sequence. The handler can’t change the result of operation but can register the fact of data changes.
- void createDictionaryProxy(data) – calls when an inner dictionary value is requested from the base dictionary If the handler is omitted no proxy will be created for any of inner dictionary values.
- void createSequenceProxy(data) – calls when an inner sequence value is requested from the base dictionary. If the handler is omitted no proxy will be created for any of inner sequence values.
For each returned Dictionary-like and Sequence-like object the proxy object creates a new wrapper (using new proxy object with the same settings as an original one) and returns it. It allows to control access to data for all descendant fields of complex data object.
Basic objects comparison
The basic data objects support comparison. Only objects with the same type can be compared. The scalar types use built-in comparing strategy. For containers, the comparing function uses item-by-item comparing. The object pointers compared by its value.
Name storing optimization
The dictionary object stores all string keys for its data. If we have a lot of Dictionary objects with the same structure, the multiple identical strings are stored that could be not optimal. For solving this problem the Dictionary can store only the 64-bit hash of key string. The real strings are stored in the global object which provides them by request basing on their hash. At run-time, the code components access to the directory using string keys which are automatically converted into their hashes during compilation (using compile-time computations).
Generic logical operations
Add
Performs logical addition/summation of two operands. If operation is performed under the operands with different types then the second operand logically converted to the type of the first operand.
| Type | Result calculation |
| Null | Null |
| Integer | val1 + val2 |
| String | val1 + val2 |
| Boolean | val1 OR val2 |
| Dictionary | Merge val1 and val2 |
| Sequence | Merge val1 and val2 |
| Object | Null |
Data packet logical operations
Field extraction
The function extracts the field by specified path from container and returns it. The following notation is used for a path:
fieldName1.fieldName2[collIndex1]…
If one of the fields in the specified path is not found the exception is returned. The exceptions-safe variant of function returns the specified default value in case of any error. If the path is empty, the source container is returned.
Fields transformation
Function gets the specified set of fields from source container, transforms them according to the specified rules, writes the results to the new container and returns it. The set of fields is specified as a Dictionary or as a Sequence. In case of Sequence, the each element is the name of field for transformation and the value is Null. In case of Dictionary the key is the name of field for transformation and value is the one of following variants:
- transformation command – in this case the specified command is called and the old value of field is specified as “data” parameter. The result of the command is the new value of a field.
- other type of variant – the specified variant become a new value of a transformed field.
If the empty set of fields is specified the function returns the empty container. If the data of a new field is Null then this field isn’t added into the result container. If the field doesn’t exist in the source container, the new field is added into the destination one.
Logical conversions
Logical conversion shall be initiated explicitly by function calling (convert<ResType>(SrcType val)). There are no hidden conversions.
Conversion to Boolean
| Type | Result calculation |
| Null | false |
| Integer | val != 0 |
| String | !val.empty() |
| Boolean | val |
| Dictionary | !val.empty() |
| Sequence | !val.empty() |
| Object | val != null |
Conversion to Integer
| Type | Result calculation |
| Null | 0 |
| Integer | val |
| String | string (decimal, hexadecimal or octal base) to integer or 0 in case of error |
| Boolean | 0 if false otherwise 1 |
| Dictionary | val.size() |
| Sequence | val.size() |
| Object | 0 if null otherwise 1 |
Conversion to String
| Type | Result calculation |
| Null | “” |
| Integer | decimal string |
| String | val |
| Boolean | “false” if false otherwise “true” |
| Dictionary | “{}” |
| Sequence | “[]” |
| Object | Hex CLSID representation |
Conversion to Dictionary
| Type | Result calculation |
| Null | {} |
| Integer | {“data”: val} |
| String | {“data”: val} |
| Boolean | {“data”: val} |
| Dictionary | val |
| Sequence | {“data”: val} |
| Object | {“data”: val} |
Conversion to Collection
| Type | Result calculation |
| Null | [] |
| Integer | [val] |
| String | [val] |
| Boolean | [val] |
| Dictionary | [val] |
| Sequence | val |
| Object | [val] |
Objects serialization/deserialization
The Variant supports native serialization and deserialization into/from JSON format. During deserialization, all the hierarchy of data packet is reconstructed.
The serialization mechanism for all objects is based on the Variant serialization. All objects which support serialization shall have an ability to save its state into Variant object. During serialization for each pointer to the external object, the Variant calls serialization methods using the ISerializable interface. These methods return the Variant which stores the state of the serialized object.
The Variant supports serialization of stream objects. For serialization, the steam object shall provide the IReadableStream interface. All stream objects are encoded using Base64 encoding and saved into JSON representation.
In the process of deserialization, the Variant, in turn, creates all serialized external objects using JSON data as a source. For doing that for each level of data hierarchy the deserialization procedure searches for a special $$clsid field which stores the identifier of a class for a stored object and calls an appropriate class factory for object creating. The class factory receives the Variant object as a representation of serialized object data as a parameter. This data is used by the object’s constructing function for restoring the serialized object state. The streams also use this method of deserialization. During deserialization their content is decoded from Base64 representation, the new stream is created according to specified $$clsid, and the data is written into this new object.
Errors processing subsystem
The errors processing subsystem supports two approaches supplement each other – errors codes and exceptions. The function is free to use any of means of errors processing: it can return an error code or throw an appropriate exception. Each exception is mapped to a particular error code. Moreover, the components can have two variants of specific function – one which returns error codes (for providing exceptions free guarantee) and the second which throws an exception. The general recommended approach is to use error codes in the case when a probability of error is high or if the returning of an error is a “normal” behavior (for example, the stream had been read till the end). When the error situation is rare and error situation means “real” error (for example, out of memory), the usage of exceptions is preferable.
Error codes
The error codes are the base of errors processing system. Error code is an integer value with the following idea Currently implemented: Undefined = -1, OK = 0, LogicError, InvalidArgument, … <and more named errors without int values, and, I think, will have int code >0 >
- 0 – no error;
- > 0 – no errors, but there are special cases;
- < 0 – error;
According to this idea all the return statuses are defined. The applications is also uses this code as a result during termination.
The application uses the predefined set of general error codes. These error codes are used in different parts of platform-independent code, so that the error codes are also platform-independent. The common platform-independent code can only manipulate with these general error codes. All dependencies are hidden in the components which provides the functionality for the certain platform.
However each platform-specific code can manipulate with platform-specific system errors. All platform-specific codes shall be converted to the general error codes at the output interfaces of platform-specific components. For this conversion, the appropriate common system-specific API is provided.
Error groups
The error codes are grouped into the logical groups. At least the following groups are present:
- Logical errors – are errors which occur as a result of invalid usage of components (functions, modules). Examples: invalid parameter, bad type cast, out of bound and so on;
- Runtime errors – are errors which occur during program execution because of external (not relating to the application code) factors; Runtime errors group, in turn, has other subgroups, which are responsible for different types of errors, such as:
- System errors – contains errors which occur as a result of invalid system calls. This type of errors always has the system-specific error code and message in the description, but any system-specific error is always converted to the generic error code by system-specific component, which generates and/or processes it;
- IO errors – contains IO specific errors;
- and so on…
Exceptions
Each exception class has an underlying error code. The exception classes are linked into hierarchy according to the error groups. So we have at least the following hierarchy:
/Exception
/LogicalError
/RuntimeError
/SystemError
/IOError
...
The exception handlers can use this hierarchy for catching both the certain exceptions and exception groups. The exception handler for generic Exception class can handle all c++ exceptions.
Standard (std) c++ exceptions are also translated to this hierarchy. For doing that, the special macroses can be used.
Exceptions save information about the place of appearing in the source code. However, they don’t store the full stack trace of calls for all parent procedures automatically. If the call stack is necessary then the developer can use prologue/epilogue macroses in each level of calls for storing this information. The information about a call trace is saved in the exception object.
Processing of unhandled exceptions and system errors
There are error situations when the application can’t handle the error (access violation, out of memory, stack overflow and so on). As a result of it, the application needs to be terminated. However, the application shall detect these situations and saves the diagnostic information for postmortem analysis. The OS and C++ CRT provides the several handlers for processing some unexpected situations.
- ::SetUnhandledExceptionFilter (Windows only)
- std::set_unexpected
- std::set_terminate
- _set_purecall_handler
- _set_invalid_parameter_handler
- _set_new_handler
- _set_abort_behavior
The application set up handlers for these situations and saves information to the log file and make a dump file for the current process. The dump file is saved into sub-folder /dump/ of the application working folder. The dump file’s name has the following format:
{app-name}-{YY}{MM}{DD}-{HH}{mm}{SS}-{pid}-{tid}-{errcode}.dmp
where:
- {app-name} – application name; fact, {app-name} is module name, e.g. “someapp.exe”.
- {YY} – year;
- {MM} – month;
- {DD} – day;
- {HH} – hour (0-24);
- {mm} – minutes;
- {SS} – seconds;
- {pid} – process Id;
- {tid} – thread Id (within the dump appeared);
- {errcode} – Exception error code;
Core object
All basic service functions of the core library are implemented in the core object. This object is an singleton which is created during the first call of any library function. In case of using dynamic libraries this object instance shall be shared between all of them. This object performs access the following functionality:
- Objects management (including object catalog service)
- Memory management
- Log management ???
- Configuration management
The functional of this object is described below (in the description of basic subsystems).
Memory Management
The library performs memory management for all objects. For doing that the library provides own methods for memory allocation/deallocation/reallocation. All allocation functions return smart pointers. The allocated memory automatically freed when the smart pointer is destroyed.
In addition, the memory manager override the following standard functions: new(), new[], delete, delete[]. All objects shall use these overridden methods for memory allocation.
The overridden version of functions includes additional parameters which show the place of memory allocation in the source code. These parameters are used both for debugging purposes and for memory leaks detection.
Memory leaks detection
- Allocator tracking
- Objects tracking
Objects management
Objects and interfaces
EDR The COM-like ideology is used. All logical entities are represented by objects. The objects implement public interfaces. Generally, all interaction between objects is realized using these interfaces. The real object’s interface is hidden. Almost all objects are included in the single objects hierarchy. The interface IObject is the root of this hierarchy. All other interfaces inherit it. This interface declares the basic functions which have to be implemented by each object in the hierarchy. One object can provide several interfaces and one interface can be requested from another using common queryInterface() function. If the requested interface is not provided by the object, then queryInterface() function throws an exception (or return null pointer).
Objects creation and life-cycle
All objects have the single place of creation – function createObject(). All other procedures use this function for creating objects. This function uses the Class Factory idiom for creating a new object. Each object type (class) has a unique class identifier (clsid) and own class factory object. A class factory object is automatically generated during class descriptor declaration. All class descriptors are declared in the description of a certain static library (which is a contains these objects). At the startup, all class descriptors register own class factories in the object manager where they become accessible for createObject() function. In addition, createObject() can create object using class name createObject<ClassName>.
The createObject() function gets the clsid as a required parameter and returns a smart pointer to the new object. Being created, all objects can be referenced only by using smart pointers. The smart pointer controls the object’s lifetime and can provide different sharing semantics. The std::shared_ptr() and std::unique_ptr() classes are used as a smart pointers. The object will be destroyed when there are no references to it. Important to understand, that only one smart pointer can be the owner of the object. Other objects or the object himself can’t create new smart pointers directly from a raw pointer to object. If the object has to pass the pointer to himself to the other function it can’t use this member directly but has to receive the smart pointer to this using getPtrFromThis() service function (this function uses get_shared_from_this() idiom from the standard c++ library). Additionally, for proper destruction, all objects shall have a virtual destructor.
For exceptions safety during creation, each object can optionally implement the initialization function finalConstruct(). This function is called only from createObject() and provides additional object initialization (and deserialization). This function receives the Variant object as a parameter. This parameter contains all necessary data for proper object initialization and/or deserialization. This function is free to use exceptions in case of errors during initialization.
Catalog service
The library provides the common catalog service for data and objects storing. This catalog service provides the unified access to stored data. The catalog has an hierarchical structure and combine together different types of information. The objects can add data to the catalog or/and add itself. So the objects can provide data dynamically by using interfaces IDataProxy, IDictionaryProxy and ISequenceProxy.
The catalog is based on the set of Variant objects. It provides the access to data using paths. The path has the following format:
/Name1/.../Name2[Index1]/.../Name3[Index2][Index3]/...The catalog is created at the start of the application. At least the following data is present:
{
os: {...} // Information about current OS
app: {...} // Startup application information
objects: [...] // Current named objects
}Named objects (services)
The application can create the objects and manipulate with them. However, sometimes it is necessary to have only one instance of the object per application. These objects are called services. Each service has a unique name. A service is registered in the global catalog in the section /objects/. This section contains pointers to the named objects. The service can be requested by its unique name using queryService().
There are two types of services:
- Classic services – objects which support IService interface;
- Named objects – objects which not support IService interface. Any object can register and unregister itself in the global catalog.
The classic service is created by the object manager during the first access to it and exists until the termination of the application. This type of objects is created and controlled by the Service Manager component using IService interface. During creation, the settings for particular service are loaded from configuration section of the global catalog (see section /app/config/services/) and passed to the new service object as parameters of its finalConstruct() function. All further requests to this service will return the service instance from this catalog. The services are destroyed in the order which is opposite to the creation order. The information about each service has the following format:
{
{service-name}: // Name of registered service
{
clsid: {service-clsid}, // Service class identifier
statePath: {...} // Description of the path in global catalog for saving/loading state
... // Additional service data
},
}Service Manager controls the life-cycle of the classic service. The following methods of service are used:
- start() – starts data processing. It is called by Service Manager when the service is being created or started after stop();
- stop() – stops data processing and “freezing” the state;
- load(vState) – loads saved state Variant;
- vState saveState() – saves the service state into Variant and returns it;
- shutdown() – performs all finalization procedures. Then this method returns the control, the Service Manager deletes the service from global catalog.
Service Manager saves the state of service before shutdown. The state is saved into the stream defined in the configuration. When the new state is saved the previous state is overwritten. Next time when the service starts it gets the saved state before start and can continue to process the saved data if it is necessary. It the service doesn’t support the state saving or has no data for saving it can return the empty Variant value.
Important to understand that all services shall be thread safe. Several objects can access to the service at same time.
All objects can request any service at any moment and as a result the smart pointer to the service is returned. The objects shall avoid capturing this pointer for a long time, so they should not store it as a member if it is not really necessary. The best practice is to request the service each time then it is used (use function scope for storing of a requested pointer).
I/O subsystem
The IO subsystem uses streams ideology. Most of I/O operations and data transformations use streams as input and/or output parameters. Being created, the stream object provides abstract interfaces for data access. The components which process streams needn’t know the physical nature of the stream object. For example, the decompression module works equally with file streams and memory streams without any distinguishes.
Interfaces
The different streams are provided different I/O interfaces. The following basic interfaces are defined:
- IRawReadableStream – provides the most primitive input interface. Supports only sequential forward read;
- IRawWrittableStream – provides the most primitive output interface. Supports only sequential forward output and flushing the I/O buffers;
- ISeekableStream – Provides the stream navigation (moving read position) and getting the stream size. If the new specified position is out of stream then the exception is thrown;
- ILockableStream – Provides the locking of parts of stream. TBD
- IReadableStream – inheritsIRawReadableStream and ISeekableStream interfaces;
- IWrittableStream – inherits IRawWrittableStream and ISeekableStream interfaces and allows to set the size of the stream;
The real data processing objects combine these interfaces and provide the new own specific ones.
The I/O subsystem also provides generic functions for common stream manipulations and overloads ‘<<‘ ‘>>’ operators for standard I/O interfaces.
Basic stream objects
- File stream – provides abstraction access to the files. It provides read/write stream interfaces along with own IFile interface. The IFile interface provides all file-specific operations. Important to understand that this object provides only classical functions for a file. All specific functions such as opening file using a driver, of writing to the locked files shall be provided by other system-specific file objects.
- Memory stream – provides abstraction access to the memory buffer as stream. It provides read/write stream interfaces along with own IMemoryBuffer interface. The IMemoryBuffer interface provides all buffer-specific operations like getting a raw pointer and so on.
- Hybrid stream – provides abstract stream which stores the data both in memory and in the temporary file. For a small amount of data only memory is used but with the growth of the size the part of data is stored to the file and RAM is used only for caching. This object allows manipulating with huge streams in the most optimal way. The parameters (such as cache size) can be defined in the configuration during object creation.
Caching objects
For effective I/O operations the cache objects can be used. These objects act as an intermediary between the slow (file-like) streams and objects which use these “slow” streams. Cache objects provides the same I/O interface as underlined object. There are at least the following caching objects:
- Cache stream for raw readable streams – provides cached input for IRawReadableStream;
- Cache stream for readable streams – provides cached (in memory) input for IReadableStream;
Converters
The converters perform transformation streams. A converter gets source stream as a parameter during its construction and provides the interface for reading/writing converted data. There are at least the following examples of converters:
- Data encoders/decoders;
- Data compressors/decompressors;
- Data filters;
The converter can provide additional interfaces for advanced controlling of the transformation process. Besides the converter allows getting access to the underlying stream.
Stream Views
Dictionary Stream View
The object allows to represent the stream (file stream for example) which contains serialized data as a dictionary. The object’s clients can read and write information transparently using the dictionary interface. During construction, the view object gets the base stream as a parameter, reads the data from it filling an internal data cache. This cache is used for processing requests from clients. When the client writes data the mapper object changes the internal cache and serializes it into the base stream.
For implementing this functionality the object is based on IDictionaryProxy interface. When the client requests the data it returns a Variant variable with a wrapper object under the real data inside. This wrapper controls the access to the data and calls the view object in case of data changes. As a result, the view object can update the base stream in case of data changes. As wrapper the mapper object uses proxy data objects.
The view object supports read-only working mode. In this mode, all operations which change the data are not permitted and in case of violation, the exception is thrown.
Important to understand, that the object doesn’t monitor the external changes in the base stream. If the base stream was changed externally the object should be informed about it by calling function reload(). The function reload() can be unsafe if it is used not in read-only mode because of possible synchronization problems during simultaneous changes of the base stream by the view object and by the external system.
Logging subsystem
The logging subsystem is intended to provide diagnostic information from source code in run-time. The diagnostic messages (log messages) are outputted using global logging functions which are available from all code parts. The log messages are out into special objects (like a channels) – log sink objects. These objects transmits/saves data into the destination storage. Every sink object also defines the format of output.
In current implementation only file sink object are supported.
Logging messages
There are the following types of diagnostic messages:
- information – the diagnostic information about the current working state. This information mainly used by developers for debugging and researching purposes;
- warning – the information about important situations which are interesting both for developers and for advanced users. However this situation can’t be treated as an error;
- error – information about important unplanned situation. This information is important both for developers and advanced users. This message usually contains the place of error in source code, type of error and additional debug information such as a call trace;
For each message the date-time stamp and the id of execution thread are saved when the message is generated.
Components
In purpose of message grouping, the message can contain the component name. The component name can be defined both for each message as a parameter and for the all current module. In the last case the component marker shall be declared in the source file before outputting the log message. If the component name is not specified, the message doesn’t belong to component.
Each component can output the message to own log sink (or several sinks). The matching between components and sinks is defined in the configuration object.
Logging levels
The logging subsystem supports different levels of logging. The log level defines the amount of outputting messages. Each message has own log level. When the application is started the current log level for it is specified. Each component of the application can also have own log level. If the log level for a component is not specified the global application log level is used. If the log level of the message is greater than the current log level for the component then the message is not outputted.
The log level can have the following values:
- 5 (critical) – Only for errors and warnings;
- 4 (filtered) – Only for messages which are important from the point of view of business logic;
- 3 (normal) – Default work mode. The primary diagnostic messages are also acceptable;
- 2 (detailed) – The detailed diagnostic messages use it. This level is default for internal builds;
- 1 (debug) – The debug information is outputted;
- 0 (trace) – this level is used for receiving step traces. used only for debug purposes;
File log sink
The file log sink output information into plain text files. All files have UTF-8 encoding. The messages are outputted line-by-line. The “\n” separator is used. If the message has multiple lines then each line has the indent which has the length equals to the sum of lengths of all prefix fields (see below). If the error message has an error code then this error code has a hex format.
The message has the following format:
{datetime} {tid} [{compname}] [{type}] message
where:
- {datetime} – the date and time (has fixed length);
- {tid} – the thread identifier (4 symbols);
- {compname} – the component name (8 symbols, if it is less then dots (.) are appended, if it is greater then the name is truncated);
- {type} – the message type marker as it is shown below:
- WRN – warning
- ERR – error
- INF – information
- message – the text of message.
First four fields have fixed length and called “message prefix”.
The example and format of the log is below:
20181024-145504.254 0a24 [APPLICAT] [INF] Application started
20181024-145504.284 0a24 [APPLICAT] [INF] Config app.cfg is loaded
20181024-145505.254 0a24 [CONFIG..] [WRN] Section 'services' is not found
20181024-145504.284 0b48 [INJECTOR] [INF] New control thread is started
20181024-145614.254 0b48 [INJECTOR] [ERR] 0x0000A428 - Access denied
Can't load driver inject.sys
Call trace:
-> driver.cpp:255 (WinAPI exception: 0x80040822 - Privileged operation)
inject.cpp:295
main.cpp:28
20181024-145504.254 0a24 [APP.....] [INF] Application finishedThe file log sink supports the logs rotation. It means that then log file achieves some criteria, the new log file is created and the old one is saved as a history file. The limit of these history files is also defined in the configuration. There are several rotation modes:
- Size-based rotation – the new file is created then the size of file become greater than it is specified in config;
- Time-based rotation – the new file is created then the previous one has creation date-time older than it is specified in config (NOT IMPLEMENTED IN CURRENT VERSION);
- Instance-based – the new file is created each time then the application started. This mode can be combined with the previous ones;
Configuration of logging subsystem
The log level of the entire application or certain component can be specified at its start using command-line parameters or in the configuration object. The following parameters as supported:
- –ll {logLevel} – set application log level;
- –ll {component-name} {logLevel} – set log level for the component;
The log subsystem configuration is saved in the /log/ section of configuration object and has the following format:
{
logLevel = 2, // default log level for application
sink = [{sink-name}, ...] // default sink for log output
components = // settings for components
{
{component-name} =
{
logLevel = 3, // default log level for the component
sink = [{sink-name}, ...], // the name of sink for outputting log messages from this component
}
}
sinks =
{
{sink-name} =
{
$$clsid = {clsid-of-sink-object},
... // other sink class parameters
}
}
}
In addition, the log level can be changed at run-time. For doing that the new instance of an application is started with a special command-line parameter. The new instance changes the log settings for all other active application instances. For doing that the IPC methods are used.
Commands and messages processing
Commands processing
The core library provides high-level interface for interaction between components using commands. The are two abstractions:
- The command – this object is encapsulated the certain command identifier, identifier of executor object and command parameters. For storing this data the command uses Variant objects. The object provides ICommand interface. The command can be created beforehand and called when it needs. The command can be serialized and deserialized from file\storage\data stream. The command object can be fully or partly parameterized during creation. In case of partial parameterization, the only subset of parameters are specified. The left part of parameters set can be added into command immediately before their execution.
- The command processors – these objects can accept commands using ICommandProcessor interface and executes them and return the appropriate result. Command processors use parameters of command during execution.
The command object has the following meta-data fields:
- Callee identifier (processor) – defines the Command Processor for the command. It can be set using several different ways:
- Specifying the smart pointer to ICommandProcessor object;
- Specifying the name of service which provides ICommandProcessor interface;
- Specifying the serialized description processor objects (specifying $$clsid and other necessary parameters);
- Command identifier (command) – in the basic cases it is just a string. But in complex cases it can be the set of strings (for example identifier of module and identifier of a function inside it).
- Command parameters (params) – the Dictionary object which contains the set of named parameters. Each parameter has Variant type;
The variant object supports the simplified notation of command implementation. This implementation allows to execute commands without explicit creation of the classic Command object. For doing this, the Variant object has overloaded call operator. In case of usage this operator the Variant threats the data inside itself as a command meta-data and tries to use it for creating the Command object and call specified Command Processor object passing the specified parameters;
Call context
A command can call other commands for calculation its parameters. In turn these commands can call other commands and so on… As a result, the chain of calls is generated. This chain can have own common context. This call context is just a Variant which stores some additional parameters for the current chain call. These parameters are set up by initial caller and they are available in the context within all call chain. For supporting the call context the command should be “context-aware”. The context-aware command is the command which supports the following features:
- receive call context as an additional parameter;
- calculate its parameters taking into account the call context. If the parameter is calculated by another command and this command is also context-aware then the command calculates this parameter executing the specified command and passing the current call context into it. If the parameter is not calculated by a command or this command is not context-aware, then it is executed in a standard way.
Context-aware commands can also substitute or append some of its parameters based on context values. Also, they can even add new data into the call context if it is demanded.
Some context-aware commands
Call command
This command can call commands of external command processor like a standard command but unlike last one it accepts the call context as an additional parameter and can transform/append initial command parameters before call using data from the context. The parameters which need to be changed before the call are specified in special Dictionary or Sequence which the command receives as a parameter $ctxParams during its creation (in finalConstruct() method). This additional parameter has the following formats:
Dictionary
{
paramName: contextName,
...
}
Collection
[
contextName,
...
]When:
- contextName – the name of variable in context which has to be add into initial parameters;
- paramName – the name of initial parameter which has to be initialized by specified context variable;
When the execute() method is called, the command performs this parameters transformation.
The command also can add/change information in the call context adding result into it.
Conditional command
The object implements ICommand interface. Besides the call context, it accepts the following parameters (both in constructor and during the call):
- condition
- trueCase (optional)
- falseCase (optional)
The command tries to evaluate condition expression. If condition expression is true then command evaluates the trueCase and returns the result of evaluation as a command’s result. If condition expression is false the falseCase expression is evaluated. If the appropriate expression is not set then null value is returned.
The evaluation of condition expression means that the command just reads data and tries to convert it to the Boolean value using rules of logical conversion. If the expression is command it executes passing the call context.
The evaluation of trueCase/falseCase expression means that the command returns specified data as a result. If the expression is command it executes passing the call context.
Data processing command
The object implements ICommand interface. Besides the call context, it accepts the following parameters (both in constructor and during the call):
- operation
- operation parameters
- source operands[]
The command gets source parameters and performs the specified operation on them returning a result. The operation can be specified both as a string or ad an integer (index of operation). The type parameters and number of operands are depended on operation. The parameters and operands of the command can be calculated/changed/appended using the same mechanism as in the ‘call’ command (see above). Important to know that the command should try to use lazy calculations and don’t compute the parameters if they are not necessary (for example in OR operation)
Messages processing
Components can use messages subsystem for communication. The messages are used for sending broadcast notifications from sender to receivers. Messages don’t imply returning any result from message receivers to message sender. Each message consists of the following data:
- Id – the ANSI string that uniquely identified the type of message. Receivers use the message Id for subscribing for message of particular type and the sender use Id for sending the message.;
- Data – the Dictionary object that can contain various message-specific data. The receiver can use this data for processing message;
The messages processing is based on commands processing. When a receiver subscribes for the message it specifies the template for a command which will be called in case of message raising. It specifies itself (usually) as a processor for this command and can pass additional predefined parameters to its message handler. For each type of message the messages processor stores all command handlers for all subscribed objects. When the sender calls SendMessage() function of the messages processor, the last one creates commands basing the specified templates, put message id and data into parameters (using message field) and executes these commands.
Configuration of messages processor
The message processor not only supports subscriptions at run-time. It also processes the special section of the configuration file (app/config/messageHandlers) which describes the “offline” objects-subscribers. For each event, this section contains the sequence of command descriptors. The messages processor creates the commands basing these descriptors when the certain message is sent by the sender. This ability can be used from creation the objects -message processors which are created only when the message has occurred.
messageHandlers:
[
{eventId}:
[
{ // command descriptor
processor: {processor-descriptor},
command: {command-id},
params: {...},
},
...
],
]Messages list
| Message ID | Event parameters | Description |
| AppStarted | The application is started | |
| AppFinishing | The application is going to shutdown, but all services are available | |
| AppFinished | The application shutdown, all services are not available | |
| CloudIsAvailable | The connection with the EDR cloud is restored (after loosing connection or at first start) | |
| ConfigIsUpdated | sectionName | The specified configuration section in the global catalog is changed |
Application object
The application object represents the entire application. It is created at the start of application and controls the application lifetime. The code of this object defines the business logic and logical links between components. It provides the following abilities:
- Parameters processing;
- Basic configuration loading;
- Filling environment information into the global catalog;
- Log and error subsystem initialization;
- Processing the startup services;
- Performing the finalization procedures;
Each application instance has own specific. For customization of behavior, the Application supports two ways of extension. The first one is to create the child class from Application and override the main processing functions inside it. This method is convenient then we significantly change the logic of the application.
The second method of customization is to use the different application working modes. The Application supports special classes which provide interface IApplicationMode. This class doesn’t change but extends existing application behavior providing own main function and own command-line parameters. The application choose the current working mode using the first command-line argument as a mode name. By default the application has the following predefined working mode handlers:
- default – empty working mode for overloading in the certain projects;
- dump – provides the output of global catalog right after Application initialization;
- install – executes commands from /install/ section of config file;
- uninstall – executes commands from /uninstall/ section of config file;
All data files of the application are located in the following places:
- Application bin directory – the directory which contains an executable image of the application. Usually, this directory contains only read-only data which is included to distributive;
- Application data directory – is located in one of the sub-directories of a user profile (depending on OS and Application type). This directory contains all changeable data. If this directory is unavailable at the start then the temporary folder is used as a data directory.
Parameters processing
The application object supports the following basic command-line parameters:
- workingMode – the first argument;
- logLevel – global log level for all application;
- logPath – path to the directory with log files;
- config – path to the main configuration file;
- version – outputs current version;
The command-line parameters override the parameters from configuration file.
The parameters above are default ones. The additional parameters can be specified in application mode handlers (see API).
Configuration processing
The configuration of the application is stored in a configuration file. By default, this file is stored in the directory which is named according to the application’s name and is located in the data application folder. If the file is not found in this location the Application tries to find it in the bin folder. The configuration also can be specified by command line.
The main configuration file is not changed by Application and other components. At the start, all content of the configuration file is loaded into the global catalog (section /config/). All changes in this section of the catalog don’t affect the config file. However, the main config file can have links into other configuration files using proxy objects (such as DictionaryStreamView). The descriptions of these proxy objects are described In the main file and during the loading of the file the proxy objects are created basing these descriptors. Further access to the data in these proxy objects controlled by these objects and all variable data can be saved into other destinations (as files or network storages).
The configuration file has the following format (only basic fields are shown):
{
config: // Application configuration
{
file: "file-path" // the name of loaded configuration file
log: {...} // log subsystem parameters
services: {...} // parameters for services initialization
messageHandlers: {...} // Message handlers (see above)
install: [...] // Install commands
uninstall: [...] // Uninstall commands
user: {...} // External read/write config
... // other configuration
},
}
Environment initialization
The Application at its start initializes some important data fields in the global catalog. These static fields are basic application settings and state fields. Also, Application adds information about the current operating system. This information is supposed not to be changed during application work.
At least the following information is added (full list is in API description):
{
app: // Application configuration
{
name: "{appName}", // Specified application name
stage: "starting" | "active" | "finishing" | "finished", // Current application stage
mode: "{workingMode}", // Working mode
startTime: "{utc-time}" // Time of start for application
imageFile: "{image-file-name}", // Path to image file
tempPath: "{dir-path}" // Path to temporary directory
workPath: "{dir-path}" // Path to initial working directory
dataPath: "{dir-path}" // Path to data directory for application (in profile)
homePath: "{dir-path}" // Path to home directory
logPath: "{dir-path}" // Path to directory with log files
binPath: "{dir-path}" // Path to bin directory with the image file
... // other configuration
},
os:
{
osName: "{str}", // OS name string
osFamily: "windows" | "linux" | "macos", // OS family
osMajorVersion: {num}, // OS version info
osMinorVersion: {num},
osBuildNumber: {num},
startTime: "{utc-time}", // OS boot time
cpuType: "arm64" | "amd64" | "x86" | "ia64" | "arm", // CPU type
cpuCount: {num}, // Number of CPUs
memPageSize: {num-in-bytes},
memSizeM: {num-in-Mbytes},
hostName: {str},
domainName: {str},
userName: {str},
...
}
}Logging and errors processing
The Application initializes log subsystem using settings from log/ section of configuration file. By default, the log files are written into the log/ subdirectory of the application data directory. This subdirectory also contains the folder named dump. The error processing subsystem uses it for saving all process dumps.
The logging subsystem initialized after some initial steps (parameters and config parsing) and because of that, if Application performs the log output till logging initialization then all data is outputted to the stdout.
Objects and services initialization
The application uses messages subsystem for informing other components about changing stages of life-cycle (see Messaging subsystem). The other components can handle the initialization or finalization messages and perform specific operations on these stages. Moreover, the message processor can call the message handlers defined in the configuration file. This ability can be used for creating and starting particular services at the application start.
Queue
The queue is a safe-thread container which stores a set of data (type Variant is supported). The queue supports basic put()/get() operations. In addition, the queue supports notification callbacks. These callbacks can be specified during object creation or at run-time using API. The callbacks are called in the following situations:
- The element is added in the queue;
- The size of the queue is reached the “warning” size which is specified in the configuration;
When the callback is calling the special parameter ‘tag’ is passed. This parameter is specified in the queue configuration and is used as a context for a callback handler.
The maximal size of the queue can be specified in the configuration. When the size of the queue reaches this size the new items can’t be added (the exception is thrown) while the size of queue is not decreased.
The queue supports the limitations of put/get operations. It means that put and/or get operations can be allowed at some time. If a client tries to call operation which is not allowed then the appropriate exception is thrown;
The queue provides filtration ability. Filter can be specified in finalConstruct() of Queue. Filter is called before add an element into Queue in thread of putter (who call put). If filter skips an element, this element is not added to queue.
The queue supports serialization using standard ISerializable interface. However, the link to notification interface is not serialized and should be set after deserialization.
Queue Manager
The queue manager is a service which is provided the set of named queues for usage to other components. The particular queue can be accessed by a unique name. The queue supports dynamically adding/deleting of the queues.
As a service, the queue supports the IService interface. The following service calls are provided:
- During its creation, the service gets the configuration as a parameter and creates the set of queues according to it. All queues are disabled (doesn’t accept put()/get() calls);
- At state loading the service loads states of queues. Only persistent queues (with appropriate flag) are loaded. If the loading queue has the same name as the existing one, the old queue is replaced;
- At the start the service enables all queues (they become available for put/get operations);
- At the stop, the service disables put() operations. However, the get() operations are available for some time (the timeout is specified in configuration).
- At state saving the service saves the state of all persistent queues using serialization interface;
- At shutdown, the service frees all queues.
Thread pool
Thread pool is an object which allows executing operations asynchronously using the several threads as execution entities. This object is used in different services and as many as need instances can be created. Each instance plans own asynchronous calls completely independently from other instances. For providing asynchronous execution the object starts and controls the group of internal threads. The number of threads can be specified during object creation and can be changed at run-time by using API functions (add and delete threads). The object finishes all threads in stop() API call or in the destructor. All planned asynchronous calls will be executed before object termination. However, all new calls will be rejected when the object started stopping/terminating.
The functions, class methods, and lambdas can be the entities for asynchronous execution.
The object is thread-safe.
IPC communication subsystem
HTTP JSON-RPC client/server
The library uses HTTP JSON-RPC protocol for interaction between processes and provides HTTP JSON-RPC Server and HTTP JSON-RPC Client objects. The subsystem implements JSON-RPC v.2 communication protocol using an original specification. It means that Client and Server objects are compatible with 3-rd party solutions in protocol level. However in application level the objects are supported fixed subset of commands.
As a high-level transport protocol the objects use HTTP, so the HTTP layer determines the size and other technical specifications of requests and responses.
HTTP JSON-RPC Server
The Server object receives commands and calls their handlers using a specified target object which implements ICommandProcessor interface.
During initialization the Server gets the following settings:
- network interface for incoming connections (localhost by default);
- incoming TCP port;
- number of execution threads;
- target object which implements ICommandProcessor interface;
During the work, the Server accepts the incoming commands from callers on the determined network interface and TCP port. For each command, the server calls the appropriate command of the target object using ICommandProcessor interface and passing command parameters as a Variant-type variable. The command is executed in a server working thread. The server supports several working threads. The result of the command is unpacked from Variant to JSON format and sent to the caller back. In case of exceptions, the server sends the appropriate error message. This message includes an error code, an error message, and a call stack.
HTTP JSON-RPC Client
The Client object implements ICommandProcessor interface and receives commands using it.
During initialization the Client gets the following settings:
- server IP address;
- server TCP port;
- operation timeout (in seconds);
During the work, the Client receives a call of command through ICommandProcessor interface. The command is packed by the Client into JSON HTTP request and is sent to a server. If the connection with the server is not established yet (or was closed since the last usage) then the Client establishes a connection (using timeout) and send data. The Client waits for a response from a callee synchronously then packs it to Variant and returns to the caller. If the error response is returned the client generates appropriate exception using data from an error message
Utility objects and functions
Variant Mixer
Mix the content of two source DPs according to specified rules and provides output as a IDictionaryProxy.
Several Dictionary objects can be aggregated into one meta-object. This meta-object provides access to the data from all underlying Dictionary objects. The object uses the stack-based access model for storing and accessing to the underlying objects. It means that when someone requests data from the meta-object it redirects the request to the Dictionary object which is in the top of the stack. If this object doesn’t have this data then meta-object requests data from the next object in the stack. If data is found in one of the underlying Dictionary objects the meta-object returns it and if doesn’t – it returns an error or the default value.
Variant Matcher
Checks if the specified Variant matches the specified conditions.
Variant Transformer
Accepts the source DP and schema. It transforms the source DP according to specified schema. The following transformations are supported:
- Adding/changing static element;
- Adding/changing element using specified template string. The template data supports substitution from source DP. The following sources are supported:
- global catalog;
- source DP;
- result of specified command;
- Deleting existing element;